Among the artificial intelligence algorithms, deep learning is considered the most sophisticated one. It is assumed to scale up and adapt to any big size datasets. However, it requires heavy rounds of optimization to improve the accuracy of prediction. Predictions are best done on structured data. But many applications that make use of semantic contextual language are also making the headlines on arXiv.
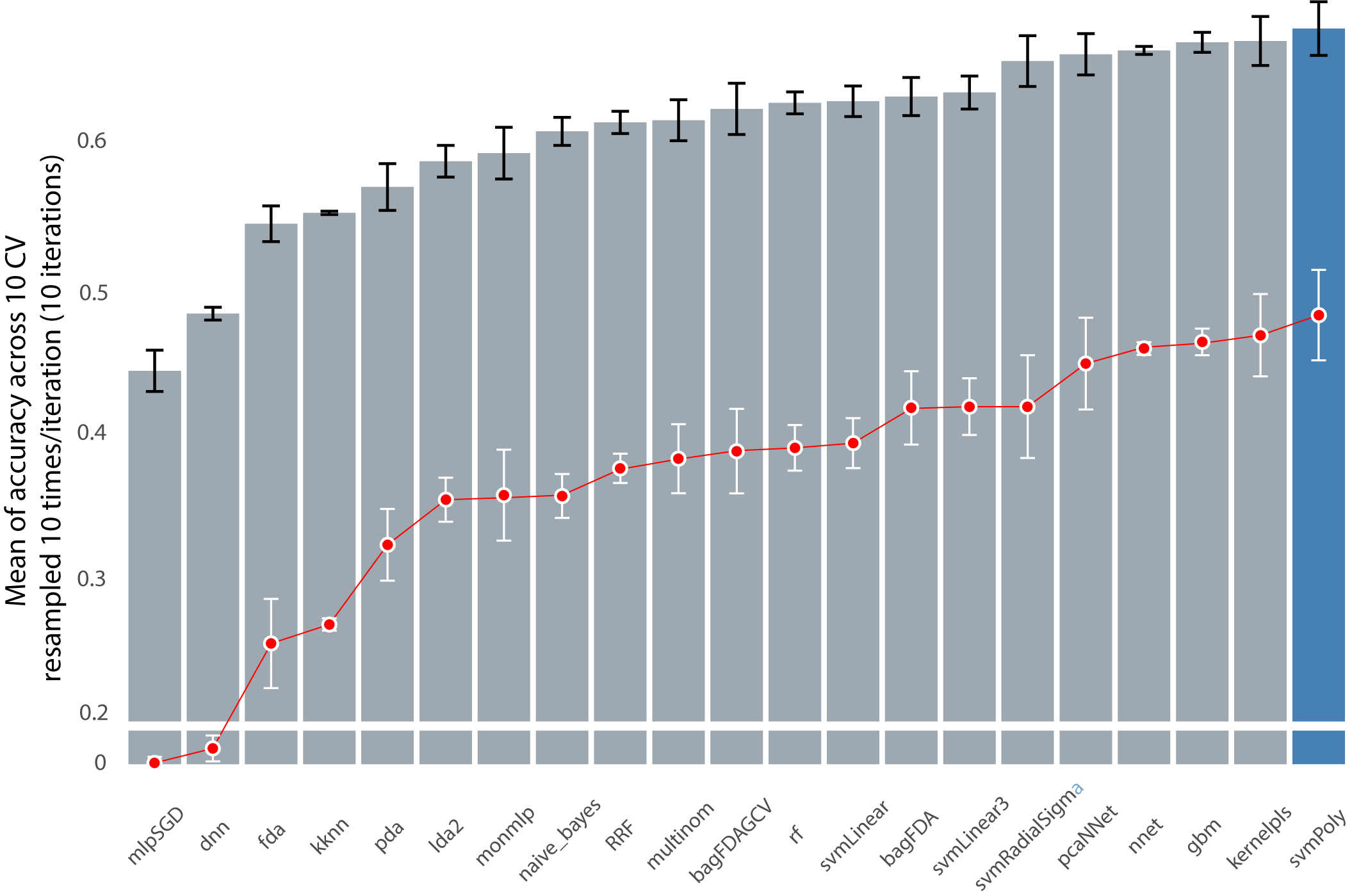
The chart below shows how support vector machines are still as accurate as the most recently developed classifier. Data used are from lymphoma cancer individuals. The goal was to use gene expression to predict these individuals prognosis after being treated with R-CHOP. The metric shown on the y-axis gives confidence on how much accurate our prediction is. We blindly load all the statistical models with data without them having prior knownledge of the diagnosis and prognosis of the individuals.
I used stochastic mini-batch sampling to correct for mismatch sample cases. Ten random seeding iterations over 10 epochs per prediction (shown as standard error bars). The red line represent the significance of each accuracy score being reported. The higher the red dot is, the fewer chance the prediction was due to random chance.